
Los avances de la Inteligencia Artificial (IA) están revolucionando casi todas las industrias, entre las que también se incluye seguros. Las compañías de seguros pueden utilizar, y están utilizando, la IA para mejorar sus procesos, reducir costos y ofrecer una mejor experiencia al cliente. En esta entrada analizaré algunas de las cuatro principales aplicaciones de la … [Leer más...] acerca de Cuatro Aplicaciones de la Inteligencia Artificial en Seguros
Quinto aniversario de Analytics Lane

Hace exactamente cinco años, el dos de mayo de 2018, publiqué las dos primeras entradas en Analytics Lane. Una publicación en la que se presentaba el blog y otra en la que explicaba cómo trabajar con archivos CSV comprimidos en R. Hoy en día es una web que el año pasado ha tenido más de un millón de visitantes únicos. Algo que se podría considerar un éxito. Aún así, sigo … [Leer más...] acerca de Quinto aniversario de Analytics Lane
Uso de comillas simples o dobles en Python

A diferencia de otros lenguajes de programación Python ofrece la posibilidad de escribir las cadenas de texto dentro de comillas simples o dobles. Aunque en la mayoría de los casos es posible usar indistintamente unas u otras, existen situaciones en las que no es así. Ante la duda de cual usar se podría consultar PEP8, pero en este caso el estándar no hace ninguna recomendación … [Leer más...] acerca de Uso de comillas simples o dobles en Python
Método de Brent e implementación en Python

El método de Brent es un método numérico para encontrar las raíces de una función que combina los métodos de la interpolación cuadrática inversa, la secante y la bisección. Convirtiéndolo en un método más robusto y eficiente que los anteriores. Veamos más en detalle los fundamentos de este método y como se puede hacer una implementación en Python.El método de … [Leer más...] acerca de Método de Brent e implementación en Python
Cuatro Aplicaciones de la Inteligencia Artificial en Banca

La Inteligencia Artificial (IA) es una tecnología que está revolucionando la sociedad y transformando casi todas las actividades. En el caso de la banca, la IA tiene la capacidad de transformar la forma en la que presta los servicios a sus clientes. Simplificado los procesos, mejorando la eficiencia, la seguridad y la experiencia de cliente. En esta publicación analizaré cuatro … [Leer más...] acerca de Cuatro Aplicaciones de la Inteligencia Artificial en Banca
Eliminar las filas con valores nulos en Pandas

Cuando se importa un conjunto de datos en un DataFrame de Pandas es posible que existan valores nulos. Cuya presencia puede afectar a las conclusiones de los análisis que se desean realizar. Para evitar esto una posible solución es eliminar las filas con valores nulos, tanto sea en una única columna, en cualquiera o en un subconjunto.Conjuntos de datos con valores nulos en … [Leer más...] acerca de Eliminar las filas con valores nulos en Pandas
Método de la interpolación cuadrática inversa e implementación en Python

El método de la interpolación cuadrática inversa es un algoritmo para localizar las raíces de funciones. La idea básica detrás de este método es utilizar una interpolación cuadrática de la función, para la que se usan tres puntos, y obtener emplear la raíz de esta como aproximación del resultado buscado. Veamos más en detalle los fundamentos de este método y como se puede hacer … [Leer más...] acerca de Método de la interpolación cuadrática inversa e implementación en Python
Diferencias entre CPU, GPU, TPU y NPU

A la hora de hablar de procesadores en muchas ocasiones aparecen conceptos como CPU, GPU, TPU y NPU. Cada una de estas siglas hacen referencia a un tipo de procesador que es adecuado para un tipo de aplicación específica, incluyendo los modelos de aprendizaje automático. La CPU y GPU son los procesadores que se encuentran en los ordenadores domésticos, aunque cada vez existen … [Leer más...] acerca de Diferencias entre CPU, GPU, TPU y NPU
Obtener los índices de los N valores máximos en NumPy

En NumPy existe la función np.max() para obtener el máximo de un vector o matriz y np.argmax() para obtener la posición del máximo. De forma análoga también existen las funciones np.min() y np.argmin() para el caso de querer obtener el mínimo o su posición. Pero, en el caso de que se desee obtener los índices de los N valores máximos en NumPy no existe una función directa y es … [Leer más...] acerca de Obtener los índices de los N valores máximos en NumPy
El método de Laguerre e implementación en Python

Cuando se necesita encontrar las raíces de polinomios complejos uno de los algoritmos que se pueden emplear es el método de Laguerre. Un método numérico propuesto por el matemático francés Edmond Laguerre en 1880. El método, al igual que el de Newton-Raphson para las raíces de funciones, utiliza las derivadas para aproximarse de manera iterativa a las raíces de los polinomios … [Leer más...] acerca de El método de Laguerre e implementación en Python
Poe: ChatGPT y otros modelos generativos en el móvil

Para poder acceder a ChatGPT es necesario acceder al navegador e iniciar la sesión con una cuenta de OpenAI, algo que puede generar algunas fricciones especialmente cuando se desee usar desde un móvil. En donde suele ser más sencillo usar una aplicación. Para estas situaciones una posible solución puede ser Poe, una aplicación para iPhone o disponible como aplicación web, en la … [Leer más...] acerca de Poe: ChatGPT y otros modelos generativos en el móvil
Gráficos de cascada: visualizar la evolución de los datos en Python
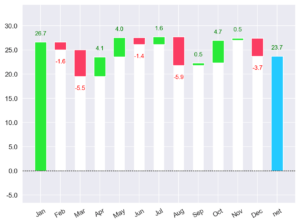
Los gráficos de cascada (Waterfall charts) son una herramienta para visualizar de una forma sencilla cómo se acumulan los valores positivos y negativos en una serie de datos. Pudiendo ofrecer en algunos casos más información que los gráficos de barras o líneas. Actualmente no existe en Matplotlib o Seaborn una forma sencilla de crear estos gráficos, pero existen otros paquetes … [Leer más...] acerca de Gráficos de cascada: visualizar la evolución de los datos en Python