
Como es habitual durante esta semana no habrá nuevas publicaciones en Analytics Lane, pero no os preocupes ya que volveremos con nuevas publicaciones el lunes 10 de abril.Aprovecho la ocasión para recordaros que para estar al día de todas nuestras publicaciones os podéis dar de alta en el boletín de noticias. Boletín que se envía todos los lunes con las últimas … [Leer más...] acerca de Semana sin publicaciones
Cuatro libros para aprender Pandas

Pandas es la librería de referencia para el manejo de datos en Python. Una herramienta compleja que puede ayudarnos a resolver una gran cantidad de problemas con los que necesitamos lidiar en el día a día como analistas o científicos de datos. Existen múltiples libros que pueden ser una excelente opción para iniciarse y profundizar en el tema. Por lo que en esta publicación he … [Leer más...] acerca de Cuatro libros para aprender Pandas
Mochi Diffusion: Stable Diffusion con Core ML
Recientemente publique el análisis de DiffusionBee, una interfaz gráfica de usuario para la creación de imágenes a partir de cadenas de texto (prompt) para Mac, y próximamente también para Windows. Un programa que facilita la evaluación de este tipo de tecnología ya que se instala como cualquier otro programa de Mac. Mochi Diffusion es una alternativa que usa la implementación … [Leer más...] acerca de Mochi Diffusion: Stable Diffusion con Core ML
Gráficos de densidad: alternativa a los gráficos de dispersión en Python
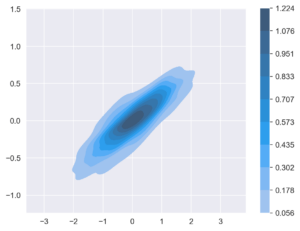
En una publicación anterior se vieron algunos de los problemas que muestran los gráficos de dispersión cuando se cuentan con grandes conjuntos de datos, proponiendo en aquella ocasión el uso de los gráficos de Hexbin como alternativa. Otros gráficos que se pueden emplear en estas situaciones son los gráficos de densidad. Unos gráficos en los que se dibujan los contornos en los … [Leer más...] acerca de Gráficos de densidad: alternativa a los gráficos de dispersión en Python
El método de Muller e implementación en Python

Uno de los métodos numéricos más sencillos para obtener las raíces de una función es el método de la secante. Existe una modificación de este método en el que se usa una aproximación cuadrática en lugar de una línea llamado método de Muller. Este cambio permite una convergencia más rápida hacia el resultado y una mayor estabilidad.El método de MullerAl igual que el … [Leer más...] acerca de El método de Muller e implementación en Python
Números aleatorios criptográficamente seguros en Node

La creación de número criptográficamente es esencial para poder garantizar la seguridad de los datos y comunicaciones frente a posibles ataques. Los números criptográficamente seguros son aquellos que se generan de tal manera que son imprescindibles para cualquier persona que no tenga acceso al sistema. Cuando no es así un atacante los podría adivinar. En JavaScript, la función … [Leer más...] acerca de Números aleatorios criptográficamente seguros en Node
Gráficos de Hexbin: alternativa a los gráficos de dispersión en Python
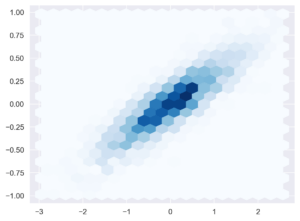
Los gráficos de dispersión son uno de los más utilizados para representar cómo se distribuyen los valores de un conjunto de datos en un plano. Son fáciles de crear y sencillos de interpretar. Aunque, cuando el conjunto de datos cuenta con centenas de registros, los gráficos de dispersión pueden ser demasiado densos para interpretarlos. En esta situación una alternativa es … [Leer más...] acerca de Gráficos de Hexbin: alternativa a los gráficos de dispersión en Python
El método de Steffensen e implementación en Python

El método de Steffensen es un algoritmo para encontrar las raíces de una función propuesto por el matemático danés Johan Frederik Steffensen en 1924. Siendo un método que suele converger rápidamente a la solución. Además, a diferencia del método de Newton, no es necesario disponer de la función deriva, por lo que su implementación es más sencilla.El método de … [Leer más...] acerca de El método de Steffensen e implementación en Python
Modelos de aprendizaje automático con ChatGPT en español

Hace unas semanas publiqué una entrada en la que evalúe las posibilidades que tiene ChatGPT para la creación de modelos de aprendizaje automático. Comprobando que es una herramienta que puede servir de ayuda para aquellos que comienzan. En aquella ocasión trabajé con la herramienta en inglés, debido a que este es el idioma en el que suelen entrenarse los modelos y, por lo … [Leer más...] acerca de Modelos de aprendizaje automático con ChatGPT en español
Uso del método de Pandas diff() con cadenas de texto

El método diff() de Pandas permite obtener la diferencia entre los valores de un registro y el siguiente para todos una serie. Aunque solamente funciona cuando las series contienen valores de tipo numérico o fecha, no cadenas de texto. Si se necesita saber cuándo los valores de una serie con texto cambian de un registro a al siguiente, será necesario crear un método equivalente … [Leer más...] acerca de Uso del método de Pandas diff() con cadenas de texto
El método de las aproximaciones sucesivas e implementación en Python

Entre los métodos numéricos para obtener la raíz de una función más sencillos de implementar se encuentran el método de las aproximaciones sucesivas. El cual se basa en el uso de una función que aproxima la solución para obtener esta de una forma iterativa. Siendo una alternativa a otros métodos numéricos como pueden ser los métodos de la bisección, la secante o el de … [Leer más...] acerca de El método de las aproximaciones sucesivas e implementación en Python
Incluir fórmulas en la documentación de TSDoc

Posiblemente la forma más sencilla para crear la documentación de una librería escrita en TypeScript es usar TSDoc. Un formato estándar para escribir los comentarios a partir del cual se puede extraer información. Así, simplemente escribiendo los comentarios de las funciones, clases y métodos se crea y actualiza la documentación del proyecto. En el caso de trabajar con … [Leer más...] acerca de Incluir fórmulas en la documentación de TSDoc