
Tal día como hoy hace tres años, en 2018, publicaba una entrada de presentación y la primera entrada del blog. Lo que en aquel momento era un simple experimento se ha convertido tres años más tarde en este proyecto. El cual, en cierta medida, aún sigo considerando como un experimento en el que publicar textos relacionados con la Ciencia de Datos, Criptografía y Aprendizaje … [Leer más...] acerca de Tercer aniversario de Analytics Lane
Muestreo de Thompson y BayesUCB para un problema Bandido Multibrazo (Multi-Armed Bandit)

El Muestreo de Thompson y BayesUCB son dos algoritmos basados en ideas bayesianas con los que es posible obtener buenos rendimiento en problemas tipo Bandido Multibrazo.Muestreo de ThompsonUno de los algoritmos más antiguos que se utilizan para seleccionar los bandidos en problemas tipo bandido multibrazo es el Muestreo de Thompson ("Thompson Sampling"). Siendo un … [Leer más...] acerca de Muestreo de Thompson y BayesUCB para un problema Bandido Multibrazo (Multi-Armed Bandit)
Truco: Aplicación para identificar símbolos LaTeX
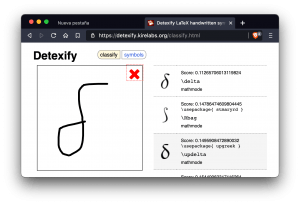
Una de las características importantes de los Jupyter Notebook es la posibilidad de incluir ecuaciones con notación LaTeX en los comentarios Markdown. Algo que facilita enormemente la documentación de los Notebooks. Para lo que solamente es necesario unos conocimientos básicos de LaTeX. A pesar de ello, a la hora de crear una ecuación, puede ser posible no acordarse de cuál es … [Leer más...] acerca de Truco: Aplicación para identificar símbolos LaTeX
Pandas: Cómo convertir un Dataframe en una lista de listas por filas o columnas

En esta entrada vamos a ver cómo se puede convertir fácilmente el contenido de un DataFrame en una lista, realizando el proceso tanto por filas como por columnas. Un truco con el que se puede cambiar el tipo de dato en función de nuestras necesidades.Creación de un DataFrame de ejemploEn primer lugar, es necesario disponer de un DataFrame, a ser posible pequeño para ver … [Leer más...] acerca de Pandas: Cómo convertir un Dataframe en una lista de listas por filas o columnas
UCB1-Normal para un problema Bandido Multibrazo (Multi-Armed Bandit)

En entradas anteriores de esta serie se han visto diferentes versiones de las estrategias UCB aplicadas a la resolución de un problema tipo Bandido Multibrazo: UCB1, UCB2 y UCB-Tuned. Estrategias que han demostrado unos excelentes resultados. Otra versión de UCB con la que se suele obtener buenos resultados es UCB1-Normal, una modificación de UCB1 en la que se asume una … [Leer más...] acerca de UCB1-Normal para un problema Bandido Multibrazo (Multi-Armed Bandit)
Cómo combinar dataframes en R

Suele ser habitual que los conjuntos de datos con los que trabajamos no se encuentren en una única tabla. Por ejemplo, los datos que identifican al cliente y las operaciones que este ha realizado. Una forma puede ser unirlos en una base de datos mediante un comando SQL. Aunque también se pueden combinar dataframes en R directamente, usando para ello la función … [Leer más...] acerca de Cómo combinar dataframes en R
Mejorar el rendimiento en Jupyter con Cython

Cython es una librería de Python con la cual se puede aumentar fácilmente el rendimiento de nuestro código en más de un orden de magnitud. Lo que se puede conseguir incluso sin la necesidad de incluir cambios en el código. Anteriormente he escrito una entrada con los fundamentos de esta librería y cómo mejorar el rendimiento de los archivos py. En esta ocasión se explicará cómo … [Leer más...] acerca de Mejorar el rendimiento en Jupyter con Cython
UCB1-Tuned para un problema Bandido Multibrazo (Multi-Armed Bandit)

La semana pasada hemos visto UCB2, un algoritmo que ha ofrecido mejores rendimientos que UCB1 para nuestros bandidos basados en una distribución binomial. En esta ocasión vamos a ver UCB1-Tuned (también conocido como UCB-Tuned), una mejora de UCB1 en el que se modifica la fórmula con la que se calcula el límite de confianza superior.UCB1-TunedEl método UCB1-Tuned … [Leer más...] acerca de UCB1-Tuned para un problema Bandido Multibrazo (Multi-Armed Bandit)
Aplicar el método D’Hondt en Excel
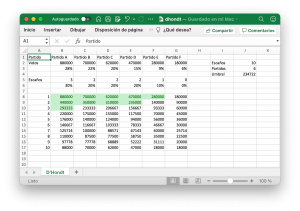
El método D'Hondt es un algoritmo para asignar escaños a las listas electorales empleado en los sistemas de representación proporcionales. Sistemas en los que se busca asignar un número de escaños proporcional a la cantidad de votos recibidos. Esto es, en el caso de que una lista reciba un veinticinco por ciento de los votos debería recibir una cantidad similar de escaños, lo … [Leer más...] acerca de Aplicar el método D’Hondt en Excel
Cómo encontrar la posición de elementos en una lista de Python

Localizar la posición de un elemento dado en una lista es una tarea bastante habitual. Por ejemplo, cuando necesitamos localizar los valores máximo o mínimo. Para esta tarea se puede usar el método index() de las listas de Python o, cuando estamos trabajando con vectores de NumPy existe el método where(). Veamos a continuación cómo encontrar la posición de elementos en una … [Leer más...] acerca de Cómo encontrar la posición de elementos en una lista de Python
Disponible JupyterLab 3.0

Ya se encuentra disponible la versión 3.0 de JupyterLab, una versión que incluye múltiples novedades. Entre las que se puede destacar el lanzamiento de un nuevo depurador visual con el que es más fácil localizar errores en nuestro código. Además de esta novedad se puede destacar otras como:Es posible configurar la interfaz de JupyterLab en múltiples idiomasLa tabla de … [Leer más...] acerca de Disponible JupyterLab 3.0
UCB2 para un problema Bandido Multibrazo (Multi-Armed Bandit)

En la entrega anterior de esta serie hemos comenzado a ver cómo aplicar los métodos UCB (Upper Confidence Bounds) para resolver un problema del Bandido Multibrazo. Métodos en los que se estima un límite de confiaban superior para la recompensa de cada uno de los bandidos. Seleccionando en cada momento el que tenga la recompensa media más el límite de confianza mayor. En esta … [Leer más...] acerca de UCB2 para un problema Bandido Multibrazo (Multi-Armed Bandit)