
En Python, trabajar con números grandes puede ser un reto en términos de legibilidad. Al lidiar con cifras que superan los miles, resulta difícil identificar a simple vista si el valor es de cientos de miles, millones o decenas de millones. Un problema que puede complicar la revisión del código y aumenta el riesgo de errores.Afortunadamente, Python ofrece una solución … [Leer más...] acerca de Truco: Usar separadores de miles en Python para números grandes
Python
Python es un lenguaje de programación interpretado con una filosofía basada en la legibilidad del código. Un lenguaje que gracias posee un gran ecosistema de librerías para la ciencia de datos. Por lo que es uno de los más populares en la actualidad entre los científicos de datos. Además, es uno de los lenguajes más deseados y adorados por los programadores según las encuestas de Stack Overflow.
Python es un lenguaje de programación interpretado de propósito general que obliga al uso de una sintaxis clara, gracias a la cual el código es altamente legible. Siendo un lenguaje potente y fácil de aprender. Además, permite utilizar múltiples paradigmas de programación. Lo que permite usar desde programación orientada a objetos, pasando por programación imperativa o funcional.
Los paquetes de Python más utilizados por los científicos son:
- NumPy: permite el tratamiento de datos basados en matrices,
- Pandas: ideal para la manipulación de datos heterogéneos mediante objetos DataFrame,
- SciPy: implementa tareas habituales en computación científica,
- Matplotlib: facilita la visualización de datos y scikit-learn creación de modelos de aprendizaje automático.
Las publicaciones de esta sección versan sobre estas librerías y las bases del lenguaje.
Optimización con Chunks en archivos grandes: Uso de pd.read_csv() con el Parámetro chunksize

Trabajar con grandes volúmenes de datos en Python puede ser un desafío, especialmente al manejar archivos extensos. Intentar cargar archivos CSV con cientos de miles de filas directamente en memoria puede generar errores por falta de memoria o ralentizar significativamente el proceso, particularmente en entornos con recursos limitados. Situación en la que se puede recurrir … [Leer más...] acerca de Optimización con Chunks en archivos grandes: Uso de pd.read_csv() con el Parámetro chunksize
FileNotFoundError en Python: Guía para abrir archivos correctamente en Python

El error FileNotFoundError en Python es uno de los problemas más comunes al trabajar con archivos. Este error ocurre cuando intentamos abrir un archivo que no existe o especificamos una ruta incorrecta. Aunque se trata de un problema frecuente, casi siempre tiene una solución sencilla si aplicamos buenas prácticas en la gestión de archivos.En esta entrada, explicaremos cómo … [Leer más...] acerca de FileNotFoundError en Python: Guía para abrir archivos correctamente en Python
Cómo instalar paquetes en Jupyter Notebook de forma eficiente: Guía completa con ejemplo

Cuando trabajas en un proyecto en Jupyter Notebook, a menudo es necesario instalar paquetes adicionales para incorporar nuevas funcionalidades. Esto puede volverse problemático si planeas compartir tu notebook con otros usuarios, ya que pedirles que instalen manualmente los paquetes necesarios puede ser tedioso y propenso a errores.Sin embargo, existe una forma eficiente de … [Leer más...] acerca de Cómo instalar paquetes en Jupyter Notebook de forma eficiente: Guía completa con ejemplo
Optimización de cálculos vectorizados con NumPy: Aprovechando Numpy para reemplazar bucles

El uso de bucles para procesar grandes volúmenes de datos o realizar cálculos matemáticos intensivos en Python puede resultar lento e ineficiente. Aunque los bucles son fáciles de implementar y leer, la necesidad de evaluar repetidamente las mismas líneas de código limita la eficiencia del intérprete de Python, impidiendo que las operaciones se realicen de manera óptima en el … [Leer más...] acerca de Optimización de cálculos vectorizados con NumPy: Aprovechando Numpy para reemplazar bucles
Evaluar similitudes entre señales: Cómo calcular la correlación cruzada con np.correlate() en NumPy

En el análisis de señales y series temporales, una de las tareas más comunes es medir la similitud entre dos conjuntos de datos. Este proceso, conocido como correlación cruzada, es fundamental para identificar patrones recurrentes, determinar retrasos entre señales o realizar comparaciones en áreas como el procesamiento de audio, meteorología y finanzas. Sin embargo, calcular … [Leer más...] acerca de Evaluar similitudes entre señales: Cómo calcular la correlación cruzada con np.correlate() en NumPy
Anotaciones dinámicas en Matplotlib: Cómo usar mplcursors para destacar puntos clave al mover el cursor

Incluir anotaciones en gráficos es fundamental para resaltar la información relevante, especialmente al analizar grandes volúmenes de datos o cuando la interpretación de estos no es inmediata. Sin embargo, un exceso de anotaciones estáticas puede saturar los gráficos y dificultar su lectura. Por ejemplo, en un gráfico de dispersión con cientos de puntos, añadir etiquetas para … [Leer más...] acerca de Anotaciones dinámicas en Matplotlib: Cómo usar mplcursors para destacar puntos clave al mover el cursor
Comparación de arrays en NumPy: Uso de np.allclose() y np.isclose() para comparaciones con tolerancia
Cuando se trabaja con datos, comparar valores se convierte en una tarea frecuente. Sin embargo, en muchos casos, aunque los valores deberían ser iguales, no lo son debido a errores de redondeo o imprecisiones derivadas de la representación de números en punto flotante. Esto puede hacer que las comparaciones directas arrojen resultados incorrectos, lo que obliga a adoptar … [Leer más...] acerca de Comparación de arrays en NumPy: Uso de np.allclose() y np.isclose() para comparaciones con tolerancia
Anotaciones en gráficos de correlación en Seaborn: Mejorando la interpretación con etiquetas
Los gráficos de correlación son herramientas esenciales para identificar y visualizar las relaciones entre las variables de un conjunto de datos. Estos gráficos permiten representar correlaciones positivas, negativas e incluso nulas, utilizando escalas de colores para facilitar la interpretación general. Por esta razón, a menudo también se les conoce como mapas de calor.Sin … [Leer más...] acerca de Anotaciones en gráficos de correlación en Seaborn: Mejorando la interpretación con etiquetas
Tutorial: Creando un mapa interactivo con Folium en Python
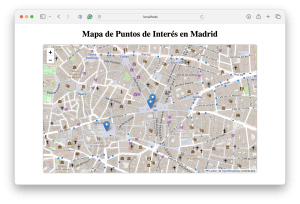
En este tutorial, se mostrará cómo crear un mapa interactivo utilizando Folium, una poderosa biblioteca de Python para visualización geoespacial. Además, se integrará este mapa en una aplicación web sencilla utilizando Flask, permitiendo que esté disponible en localhost:3000. A lo largo del tutorial, también se verá cómo obtener y mostrar puntos de interés dinámicamente en el … [Leer más...] acerca de Tutorial: Creando un mapa interactivo con Folium en Python
Uso de índices jerárquicos en Pandas: Domina df.set_index() y df.unstack()
Manejar datos tabulares de forma eficiente es una habilidad esencial en la mayoría de los análisis de datos. Sin embargo, las estructuras tradicionales con filas y columnas simples a menudo no son suficientes para capturar algunas relaciones complejas presentes en muchos conjuntos de datos. En estos casos, los índices jerárquicos en Pandas, también conocidos como índices … [Leer más...] acerca de Uso de índices jerárquicos en Pandas: Domina df.set_index() y df.unstack()
Manipulación de dimensiones en Numpy: Uso de np.reshape() y np.flatten()
Al trabajar con conjuntos de datos reales, es poco común que estos lleguen en el formato ideal para su uso directo. Por lo general, es necesario reorganizar, transformar o modificar su estructura para adaptarlos a los requisitos específicos de diferentes algoritmos o modelos. Numpy, una de las bibliotecas más populares de Python para operaciones matemáticas y manipulación de … [Leer más...] acerca de Manipulación de dimensiones en Numpy: Uso de np.reshape() y np.flatten()