
Anaconda acaba de anunciar la disponibilidad de la versión 2021.11 de su distribución de Python y R. Una de las soluciones más empleadas tanto por científicos e ingenieros de datos como en entornos de aprendizaje automático. En la nueva versión se han actualizado 170 paquetes e incluido 58 nuevos respecto a la versión anterior publicada en mayo de este año (la versión 2021.05). … [Leer más...] acerca de Disponible Anaconda 2021.11
Actuar en GTD

La última fase de GTD es actuar o hacer. El cual es el objetivo último de cualquier metodología de productivas personal, hacer el trabajo. En las cuatro fases anteriores de la metodología GTD se ha capturado, clarificado, organizado y reflexionado sobre todo las tareas, tanto las profesionales como las personales, y ahora llega el momento de actuar y aprovechar todo el trabajo … [Leer más...] acerca de Actuar en GTD
Pendrives USB dual (USB tipo-a y tipo-c)

La conexión USB tipo-c es el nuevo estándar para la conexión física de dispositivos. Un conector reversible a través del cual es posible enviar al mismo tiempo tanto datos como energía, por lo que permite simplificar la conexión de dispositivos al reducir todo lo necesario a un único cable. Un único cable que además es un estándar. Por eso los conectores USB tipo-c es el único … [Leer más...] acerca de Pendrives USB dual (USB tipo-a y tipo-c)
Actualizar las dependencias de Node a la última versión de forma automática
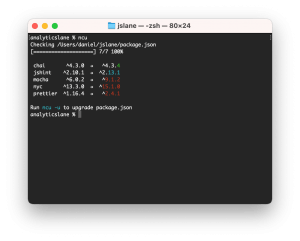
Al trabajar en un proyecto con Node generalmente se instala la última versión de los paquetes necesarios. A medida que pasa el tiempo van saliendo nuevas versiones de estos con nuevas funcionalidades, soluciones de errores y parches de seguridad. Pero, si no hacemos nada, las versiones del archivo package.json no se actualizan. Algo que, en el peor de los casos, puede exponer … [Leer más...] acerca de Actualizar las dependencias de Node a la última versión de forma automática
Eagle: primer procesador cuántico de 127 qubit de IBM
IBM acaba de anunciar un importante hito en la computación cuántica: el primer procesador que supera los 100 qubit. Lo que supone un gran avance en computación cuántica. Eagle es un procesador de 127 qubit que, según indica IBM, es el primero que no puede ser simulado mediante el uso de un ordenador clásico.Una nueva tecnología se lanzará el 23 de noviembre en el IBM … [Leer más...] acerca de Eagle: primer procesador cuántico de 127 qubit de IBM
Análisis de datos en Python al estilo Excel con Mito
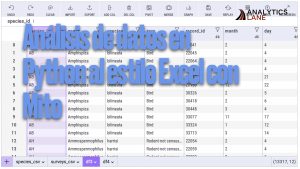
Mito es una interfaz para el análisis de datos basaos en JupyterLab con un funcionamiento similar al de las hojas de cálculo. Permitiendo llevar a cabo complejos análisis en pocos segundos, creando además de forma automática código Python con el que repetir las operaciones en cualquier conjunto de datos similar. Lo que permite crear análisis de datos en Python al estilo de … [Leer más...] acerca de Análisis de datos en Python al estilo Excel con Mito
Reflexionar en GTD
En tres publicaciones anteriores se han mostrado los pasos necesarios para poner en marcha un sistema de productividad basado en GTD. El cual comienza con la captura de todas aquellas cosas que son relevantes o pueden ser de interés para nosotros. Una vez capturadas estas es necesario clarificar cada una de ellas para saber qué son concretamente e identificar si requieren … [Leer más...] acerca de Reflexionar en GTD
Lectura y escritura de archivos Apache Arrow o Feather en R

En entradas recientes hemos hablado de las ventajas que ofrecen los archivos Apache Arrow o Feather frente a los tradicionales CSV. No solo ocupan menos espacio en disco, sino que los procesos de lectura y escritura son varios órdenes de magnitud más rápidos. Siendo ambas son grandes ventajas cuando se trabaja con conjunto de datos de gran tamaño. La única desventaja podría ser … [Leer más...] acerca de Lectura y escritura de archivos Apache Arrow o Feather en R
Pandas: Renombrar columnas en Pandas

Los DataFrame de Pandas ofrecen la posibilidad de almacenar datos con indexación, tanto para filas como para columnas. Índices que puede ser necesario cambiar. Para ello se puede usar el método set_axis(), aunque puede ser poco productivo cuando solamente se quiere cambiar unos pocos índices. En estos caso se puede usar el método rename(). Veamos a continuación la forma de … [Leer más...] acerca de Pandas: Renombrar columnas en Pandas
Organizar en GTD
Según GTD una vez aclarado el contenido de las bandejas de entrada es necesario organizar este en diferentes contenedores. Lo que se lleva a cabo en la tercera fase de la metodología: organizar. La tarea de organizar en GTD se realiza inmediatamente después de clarificar, siendo la separación entre estas dos fases más bien conceptual que operativa.Esta entrada forma parte … [Leer más...] acerca de Organizar en GTD
Función de interpolación lineal en Excel sin VBA
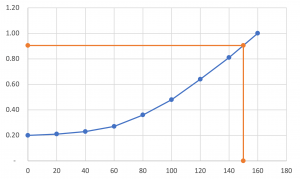
Microsoft Excel no cuenta actualmente con una función que nos permita obtener una interpolación lineal de una serie de datos. De modo que, para estimar el valor que tomaría una serie entre dos puntos es necesario hacerlo mediante las funciones de Excel o creando un macro. En el siguiente video se puede ver cómo crear una función para obtener la interpolación lineal en Excel sin … [Leer más...] acerca de Función de interpolación lineal en Excel sin VBA
Pandas: Cambiar el tipo de columnas en un DataFrame
Al crear un nuevo DataFrame en Pandas, si no se indica de forma explícita, el constructor le asignará a cada una de las series el tipo de dato que considere más adecuado. Pudiendo ser diferente al que necesitamos. Especialmente cuando en los datos originales se combinan valores numéricos con cadenas de texto. Para solucionar estos problema y cambiar el tipo de columnas en un … [Leer más...] acerca de Pandas: Cambiar el tipo de columnas en un DataFrame