
A finales del año pasado saltaba la noticia de la existencia de una vulnerabilidad crítica en Apache Log4j, afectando a millones de aplicaciones y servicios que usaban esta librería para la creación de los logs. Poniendo en jaque a miles de pequeñas, medianas y grandes empresas. La gravedad del fallo de seguridad se puede ver en el hecho de que la noticia ha llegado a las … [Leer más...] acerca de ¿Es sostenible la ciencia de datos basada en Software Libre?
Ciencia de datos
La ciencia de datos es un área de conocimiento interdisciplinar en el cual se utilizan procesos para recopilar, preparar, analizar, visualizar y modelar datos para extraer todo su valor. Pudiéndose emplear tanto con conjuntos de datos estructurados como no estructurados. Los científicos de datos, los profesionales de esta área deben poseer grandes conocimientos de estadística e informática. Además de conocimiento de los procesos que están modelando.
Con la ciencia de datos es posible revelar tendencias y obtener información para que tanto las empresas como las instituciones puedan tomar mejores decisiones. Basando estas así en conocimiento validado no en intuiciones.
Las publicaciones de esta sección abarca diferentes temas de áreas como la estadística, la minería de datos, el aprendizaje automático y la analítica predictiva.
Escalabilidad para Machine Learning

El concepto de escalabilidad es algo cada día más importante a la hora de desarrollar nuevas soluciones tecnológicas, incluidas en las que se implementan modelos de Aprendizaje Automático o Machine Learning. De poco sirve disponer del mejor modelo si cuando es necesario no es posible escalar para responder a toda la demanda. Esto es, si no se puede resolver en plazo todas las … [Leer más...] acerca de Escalabilidad para Machine Learning
Los tipos de aprendizaje por conjuntos (Ensemble Learning)

Al evaluar y comparar el rendimiento de diferentes modelos de aprendizaje automático es habitual observar que las mejores predicciones no siempre proceden del mismo modelo. En un subconjunto de datos los mejores resultados los ofrece la regresión lineal, pero en otro funcionan mejor los árboles de decisión. Lo que indica que el mejor modelo sería una combinación de los mejores. … [Leer más...] acerca de Los tipos de aprendizaje por conjuntos (Ensemble Learning)
Integración continua para la ciencia de datos

En los grandes proyectos de ciencia de datos aparecen problemas similares a los de los grandes desarrollos de software. Uno de ellos es la necesidad de integrar en una única solución el trabajo de todos los miembros del equipo. Para ello una de las técnicas más empleadas en desarrollo de software es la integración y la entrega continuas (CI/CD). Veamos a continuación algunas de … [Leer más...] acerca de Integración continua para la ciencia de datos
Detección de anomalías en series temporales
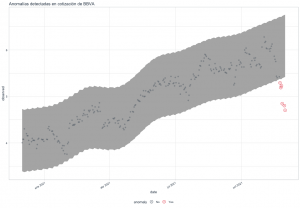
La detección de anomalías es un campo del aprendizaje automático con múltiples aplicaciones prácticas. Poder identificar automáticamente los datos que son atípicos para una variable permite lanzar alarmas para comprobar la existencia temprana de algún problema. Pudiendo actuar en consecuencia y minimizar las posibles consecuencias. Recientemente he descubierto un paquete de R, … [Leer más...] acerca de Detección de anomalías en series temporales
Diferencias entre Hard y Soft Clustering

El análisis de clustering o análisis de grupo es una de las técnicas más populares dentro del aprendizaje no supervisado. Cuando se dispone de un conjunto de datos sin etiquetar, esto es no se tiene un valor o etiqueta asociado a cada registro, se puede utilizar el análisis de clustering para agrupar los elementos que son similares entres sí y separa aquellos que son … [Leer más...] acerca de Diferencias entre Hard y Soft Clustering
Regresión de Vectores de Soporte (SVR, Support Vector Regression)

La Regresión de Vectores de Soporte (SVR, del inglés Support Vector Regression) es un algoritmo de regresión basado en los mismos algoritmos que usan las Máquinas de Vectores de Soporte (SVM, del inglés Support Vector Machines) para la creación de modelos de clasificación. Aunque existen algunas diferencias debido a que la salida de una regresión es un valor real y no una … [Leer más...] acerca de Regresión de Vectores de Soporte (SVR, Support Vector Regression)
¿Siguen las visitas a Analytics Lane la ley de la potencia?
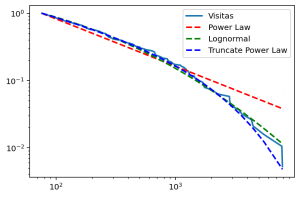
Hace un par de años, en los primeros días del blog, intenté comprobar si las visitas a Analytics Lane seguían la ley de la potencia. Sin obtener en aquel momento un resultado claro. La ley de la potencia es una relación entre magnitudes que se puede observar en múltiples fenómenos de carácter físico, biológico o debido a la actividad humana. Ahora, una vez han aumentado el … [Leer más...] acerca de ¿Siguen las visitas a Analytics Lane la ley de la potencia?
Libros para iniciarse en Machine Learning disponibles en castellano

Existen decenas de buenos libros para iniciarse en Machine Learning, pero la mayoría de ellos están solamente disponibles en inglés. Por eso mucha gente que se inicia en el tema me consulta por opciones en castellano para evitar que el idioma sea una barrera de entrada. Afortunadamente cada vez hay más libros, tanto traducidos como originalmente, con los que aprender más sobre … [Leer más...] acerca de Libros para iniciarse en Machine Learning disponibles en castellano
Significado de p-value en Machine Learning

Una duda habitual que me suelen plantear los alumnos al comenzar en Machine Learning, y también no tan novatos, es que significan los p-value. Además de por qué se deben rechazar los resultados cuando estos superan 0,05. Básicamente este valor es la probabilidad de que, con los datos disponibles, la hipótesis nula, la opuesta a la que deseamos rechazar, sea verdadera. Por eso, … [Leer más...] acerca de Significado de p-value en Machine Learning
Diferentes modelos de aprendizaje no supervisado

Los modelos de aprendizaje automático se dividen en tres familias: el aprendizaje supervisado, el aprendizaje no supervisado y el aprendizaje por refuerzo. Siendo posiblemente el más utilizado el aprendizaje no supervisado. Principalmente debido a que no necesita datos etiquetados con para el proceso de entrenamiento, como es requerido en aprendizaje supervisado. A … [Leer más...] acerca de Diferentes modelos de aprendizaje no supervisado
Librería Python para resolver el Bandido Multibrazo (Multi-Armed Bandit)

Durante los últimos meses he estado dedicando las entradas de los viernes a describir diferentes estrategias existentes para abordar los problemas tipo Bandido Multibrazo (Multi-Armed Bandit) e implementarlas en Python. Creando de este modo una colección de código que puede ser interesante para la realización de comparaciones entre algoritmos. Por eso, recientemente he … [Leer más...] acerca de Librería Python para resolver el Bandido Multibrazo (Multi-Armed Bandit)