
Apache Arrow y Parquet son dos formatos modernos para con los que es posible conseguir archivos más pequeños que CSV, además de unos menores tiempos de lectura y escritura. Veamos a continuación las diferencias que existen entre Apache Arrow y Parquet.Apache ArrowApache Arrow es una biblioteca, disponible para múltiples lenguajes de programación, que proporciona … [Leer más...] acerca de Diferencias entre Apache Arrow y Parquet
Python
Python es un lenguaje de programación interpretado con una filosofía basada en la legibilidad del código. Un lenguaje que gracias posee un gran ecosistema de librerías para la ciencia de datos. Por lo que es uno de los más populares en la actualidad entre los científicos de datos. Además, es uno de los lenguajes más deseados y adorados por los programadores según las encuestas de Stack Overflow.
Python es un lenguaje de programación interpretado de propósito general que obliga al uso de una sintaxis clara, gracias a la cual el código es altamente legible. Siendo un lenguaje potente y fácil de aprender. Además, permite utilizar múltiples paradigmas de programación. Lo que permite usar desde programación orientada a objetos, pasando por programación imperativa o funcional.
Los paquetes de Python más utilizados por los científicos son:
- NumPy: permite el tratamiento de datos basados en matrices,
- Pandas: ideal para la manipulación de datos heterogéneos mediante objetos DataFrame,
- SciPy: implementa tareas habituales en computación científica,
- Matplotlib: facilita la visualización de datos y scikit-learn creación de modelos de aprendizaje automático.
Las publicaciones de esta sección versan sobre estas librerías y las bases del lenguaje.
Uso de Parquet para guardar los conjuntos de datos de forma eficiente en Pandas

Los formatos de archivo para el intercambio de datos más populares actualmente son CSV y Microsoft Excel. Resultando ambos poco eficientes a la hora trabajar con grandes conjuntos de datos. CSV es un formato basado en archivos de texto plano, lo que permite su edición con cualquier editor de texto, sin la necesidad de emplear un programa específico. Aunque esto también se … [Leer más...] acerca de Uso de Parquet para guardar los conjuntos de datos de forma eficiente en Pandas
Creación de tablas resumen en Python con Sidetable

Sidetable es un complemento para Pandas con el que es posible crear fácilmente tablas resumen en Python de los conjuntos de datos. Lo que consigue mediante la combinación de funciones de tabulación cruzada y recuento de datos, simplificando muchos análisis habituales.Instalación y conjunto de datos de ejemploEl método más sencillo para instalar Sidetable en Python es … [Leer más...] acerca de Creación de tablas resumen en Python con Sidetable
Visualización de valores faltantes con Missingno

Uno de los problemas más habituales en los conjuntos de datos es la existencia de valores nulos o faltantes (missing values). La existencia de estos valores suele ser una señal de una mala calidad de datos, lo que afecta a la calidad de los posibles modelos que se pueden construir a partir de ellos, por lo que es necesario conocer el volumen del problema lo antes posible. Para … [Leer más...] acerca de Visualización de valores faltantes con Missingno
¿Qué significa if __name__ == “__main__”: en Python?
Al revisar programas escritos en Python es bastante probable encontrarse con una línea de código cómo la siguiente: if __name__ == "__main__":. El código dentro del bloque if solamente se ejecutará cuando el archivo es llamado directamente con el intérprete de Python, no cuando es importado como un módulo. Permitiendo de este modo reutilizar el código de manera más sencilla. … [Leer más...] acerca de ¿Qué significa if __name__ == “__main__”: en Python?
Guardar los modelos de Scikit-learn en disco e importarlo en otra sesión

Una vez entrenado un modelo de aprendizaje automático con Scikit-learn puede surgir la necesidad de guardar este para usar en otra sesión. Posiblemente durante el proceso ha sido necesario cargar los datos, seleccionar las carteristas más relevantes, ajustar los hiperparámetros y comparar varios algoritmos de aprendizaje. Algo que no querremos repetir cada vez que necesitemos … [Leer más...] acerca de Guardar los modelos de Scikit-learn en disco e importarlo en otra sesión
Análisis de datos en Python al estilo Excel con Mito
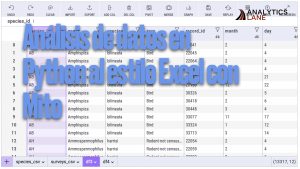
Mito es una interfaz para el análisis de datos basaos en JupyterLab con un funcionamiento similar al de las hojas de cálculo. Permitiendo llevar a cabo complejos análisis en pocos segundos, creando además de forma automática código Python con el que repetir las operaciones en cualquier conjunto de datos similar. Lo que permite crear análisis de datos en Python al estilo de … [Leer más...] acerca de Análisis de datos en Python al estilo Excel con Mito
Pandas: Renombrar columnas en Pandas

Los DataFrame de Pandas ofrecen la posibilidad de almacenar datos con indexación, tanto para filas como para columnas. Índices que puede ser necesario cambiar. Para ello se puede usar el método set_axis(), aunque puede ser poco productivo cuando solamente se quiere cambiar unos pocos índices. En estos caso se puede usar el método rename(). Veamos a continuación la forma de … [Leer más...] acerca de Pandas: Renombrar columnas en Pandas
Pandas: Cambiar el tipo de columnas en un DataFrame
Al crear un nuevo DataFrame en Pandas, si no se indica de forma explícita, el constructor le asignará a cada una de las series el tipo de dato que considere más adecuado. Pudiendo ser diferente al que necesitamos. Especialmente cuando en los datos originales se combinan valores numéricos con cadenas de texto. Para solucionar estos problema y cambiar el tipo de columnas en un … [Leer más...] acerca de Pandas: Cambiar el tipo de columnas en un DataFrame
Almacenar los datos de forma eficiente con Feather en Python

El formato de archivo CSV es uno de los más populares para el intercambio de datos. Lo que es debido a estar basado en un archivo de texto plano, por lo que puede ser interpretado prácticamente en cualquier sistema por cualquier programa. Aunque esto también es un problema, ya que un archivo CSV ocupa demasiado espacio y los procesos de lectura y escritura son lentos. Para … [Leer más...] acerca de Almacenar los datos de forma eficiente con Feather en Python
Extensiones de Jupyter Notebook para facilitar las tareas de codificación
Una de las grandes virtudes de Jupyter Notebook es la posibilidad de instalar complementos con los que extender las funcionalidades. Entre los paquetes disponibles en la actualidad posiblemente uno de los más completos es jupyter_contrib_nbextensions. Un paquete que contiene más de 60 extensiones del que podéis encontrar dos entradas anteriores analizando algunas de sus … [Leer más...] acerca de Extensiones de Jupyter Notebook para facilitar las tareas de codificación
Mejores mensajes de error en Python 3.10

Además de las mejoras de tipado y la introducción de Switch-Case otra de las novedades con las que nos encontramos al actualizar a la versión 3.10 de Python son unos mensajes de error más claros. Ahora, en muchas ocasiones, cuando el código tiene un error nos encontraremos con mensajes más útiles para identificar cuál es el problema. Lo que se va a traducir en procesos de … [Leer más...] acerca de Mejores mensajes de error en Python 3.10